Blog
運用チームの品質改善取り組みについて
2020/04/22
- #KCPS
- #運用
- #Quality Cloud
KDDIクラウドプラットフォームサービス(以下、KCPS)の運用担当 金子です。 いつもKCPSをご利用いただきありがとうございます。 2019年度に運用チームで実施しました、品質改善の取り組みについてご紹介したいと思います。
従来の監視方式
KCPSではサービス提供するための設備機器の故障検知として、SNMP-Trap監視(※1)やログ監視(※2)を採用してきました。これらは多くのオンプレミス環境の運用監視で採用されている方式で、監視対象機器が自身で検知した異常を全て運用監視者に通知し、その後監視者が状態の確認、異常時の復旧対処を実施することでサービスの品質を維持してきました。
※1:監視対象機器でのHW異常等をSNMPエージェントがマネージャへ通知する監視方式 ※2:監視対象機器内で出力されるログ構文をチェックし、”ERROR”などの特定文言が含まれる場合に通知する監視方式
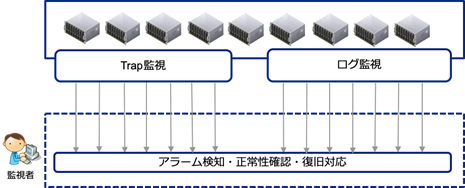
図1:従来の監視方式
2012年にサービスが開始されて以降、お客さまに提供するクラウドリソース拡大だけでなく、新機能の追加やベアメタルサーバーサービスなどの新たなサービスの提供に伴い、監視対象となる機器も増加してきました。運用者として、今後も継続的に増えていく機器に対し変わらぬ品質を維持するため、従来の監視の仕組みを根本から変える必要があると考えました。
過去の膨大な運用ナレッジをベースに内製監視システムを開発
今回、これまで実施していた機器からの状態通知を待つ、いわゆる受動的な監視方式を一新し、能動的に状態確認を行う監視システムを内製で開発いたしました。具体的な変更点と新監視方式について、「お客さまの仮想マシンで利用しているストレージ機器(機器A)のDISK故障」を例に説明いたします。
Before(Trap、ログによる監視方式) 1.機器Aがディスク機器の異常と思われる状態を検知、そのまま運用監視者に対して通知 2.機器Aからの通知を受信し運用監視者にて対応を実施 ・通知された内容を確認、機器ごとに用意された状態確認方式に従い対象機器の故障有無を確認 ・機器Aを利用しているお客さまの仮想マシンについて、問題なく稼働できているかお客さま視点での操作確認(Diskの作成、Disk利用ができるかどうか)を実施 ・確認結果として問題があった場合は復旧対処や詳細調査を実施
After(内製監視システムによる監視方式) 1.機器Aからの通知は実施せず、内製監視システムが機器Aの状態を定期的に確認 ・内製監視システムが機器Aにログインし、機器故障の有無の確認(システム確認) ・対象機器を利用している仮想マシンの操作の疑似確認(サービス確認)を実施 ・システム確認、サービス確認の両方の結果の分析し、「対処が必要」と判断された場合に運用監視者へ通知 2.監視者で通知を受信、この時点で対処が必要であることが確定しているため復旧対応を実施
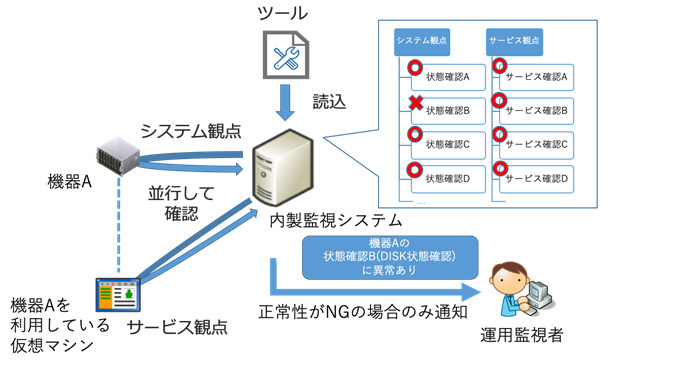
図2:内製監視システムの仕組み
KCPSではサービス開始から培ってきた数多くの運用実績と、その経験から確立された数千に及ぶ対応ナレッジが存在します。この情報を基にKCPSを構成する機器種別ごとのシステムの正常性、サービス正常性の判断基準を整理し、その結果を正常性判断ロジックとして盛り込むことで全自動での正常性判断を実現しました。
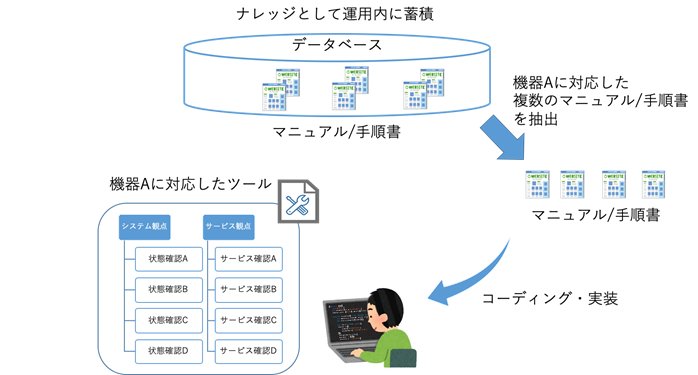
図3:ツール作成までの流れ
導入結果
従来の監視方式では、機器からの状態異常が通知されてから手動でシステム確認、サービス確認を実施し、通知ごとに10分以上の時間を要していました。今回の本内製監視システム導入により、これらの確認の手間が一切排除されました。結果として、運用監視者の稼働時間が大幅削減し、また状態の定期的な確認によって品質低下を未然に防ぎ、即時で復旧対応が可能になったことで、サービスとしてより高い品質を維持できるようになりました。
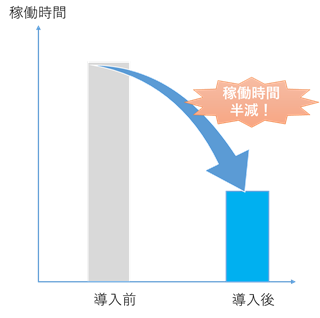
図4:内製監視サーバ導入後の稼働時間比較
まとめ
今後の更なるクラウドリソースの拡大、新サービスを見据えた時に、現状のやり方を変えてでも高い品質を実現したいという強い思いから、運用チーム主導で内製監視システムを完成させました。今後はこの変更により創出された時間をサービス改善等に用いることで、KCPSがより多くのお客さまにご満足いただけるようなクラウドサービスにしていきます。